البحث في الموقع
Showing results for tags 'data mining'.
تم العثور علي 3 نتائج
-
 السلام عليكم تواكبا مع متطلبات الواقع و المستقبل ، تم افتتاح مجموعة أقسام جديدة تختص بالبحث العلمي و علوم البيانات و من ضمنها هذا القسم ، و هو يختص بالمواضيع الخاصة بالذكاء الاصطناعي Artificial Interlligence و التنقيب فى البيانات Data Mining نذكر الزوار الجدد بقواعد المشاركة فى منتدى أوفيسنا ، و من أهمها احترام حقوق الملكية الفكرية و منع نشر أي مواد أو تطبيقات دون موافقة أصحابها.
السلام عليكم تواكبا مع متطلبات الواقع و المستقبل ، تم افتتاح مجموعة أقسام جديدة تختص بالبحث العلمي و علوم البيانات و من ضمنها هذا القسم ، و هو يختص بالمواضيع الخاصة بالذكاء الاصطناعي Artificial Interlligence و التنقيب فى البيانات Data Mining نذكر الزوار الجدد بقواعد المشاركة فى منتدى أوفيسنا ، و من أهمها احترام حقوق الملكية الفكرية و منع نشر أي مواد أو تطبيقات دون موافقة أصحابها. -
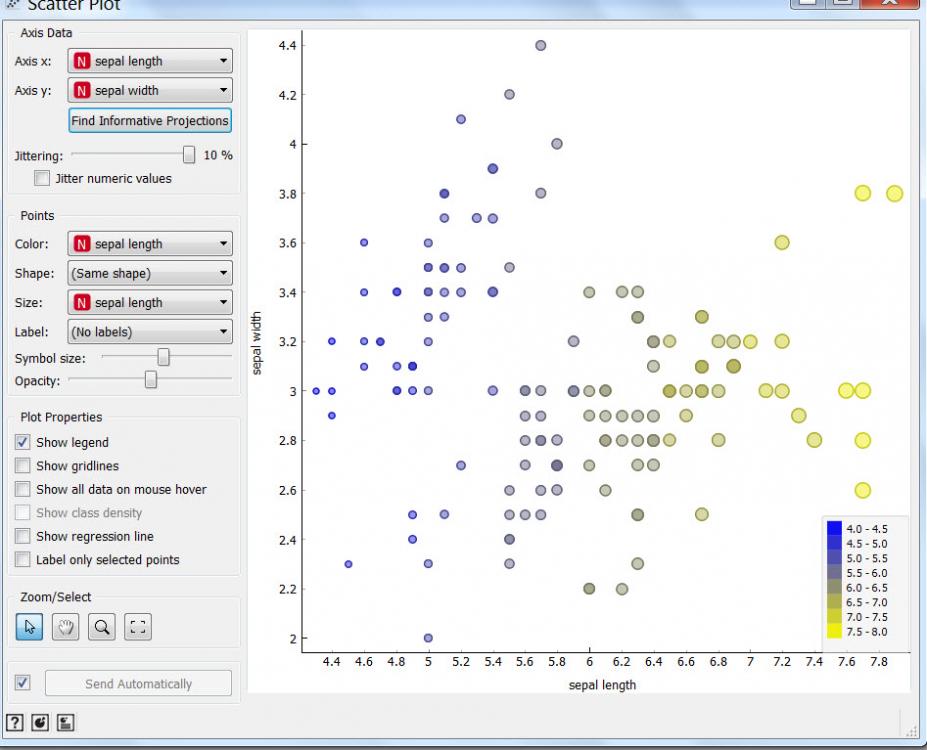
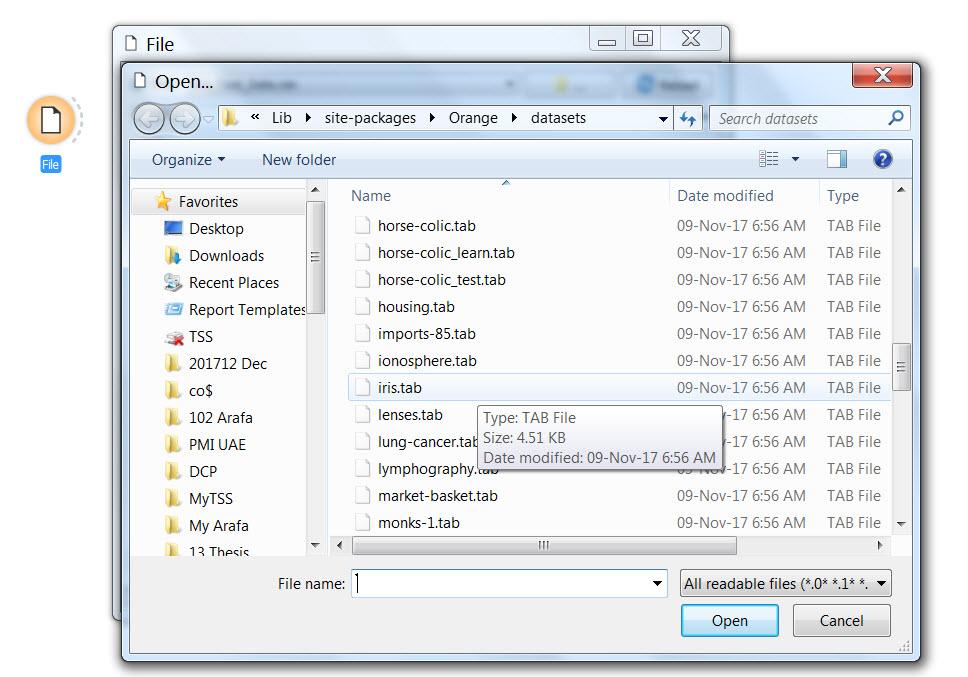
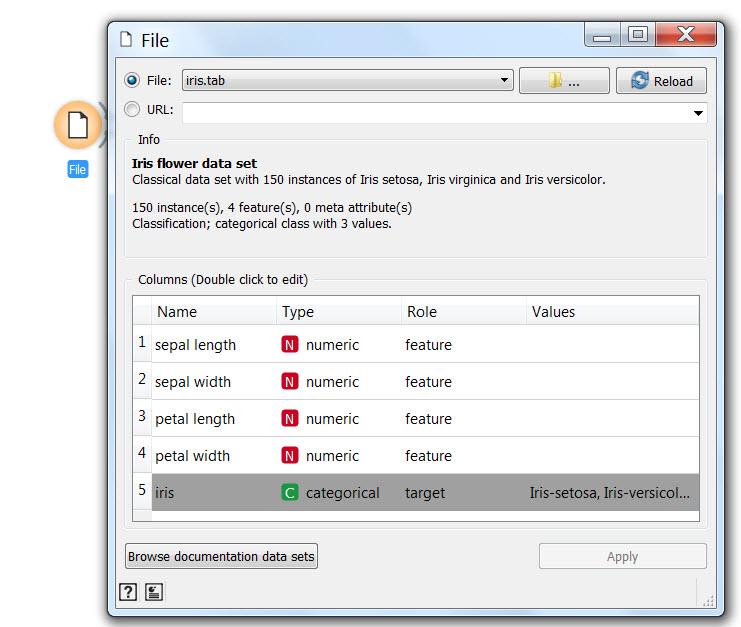
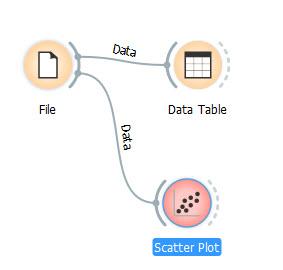
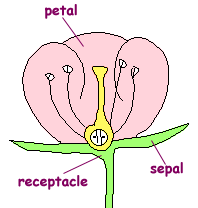
السلام عليكم مرحبا بكم فى الدرس الاول لتطبيق اورانج ربما لا يعرفه الكثيرين من غير المختصين ، و لكنه باختصار تطبيق مفتوح المصدر يحوي مستويات متعددة لتحليل البيانات ، و ليس فقط التحليل ، و لكن يتعدى ذلك الي الذكاء الصناعي Artificial Intenligence و التحليل العميق للبيانات Data Mining و يمكن استخدامه بطريقة مفيدة على مختلف المستويات. كما انه يمتاز بسهولة الاستخدام. و هذه خطوة على طريق المستقبل فى علوم تحليل البيانات Data Science و التي من اجلها افتتحنا مجموعة الاقسام التي من ضمنها هذا القسم الوليد، و الخاصة بالبحث العلمي و تحليل البيانات و الذكاء الاصطناعي و التي امل من الجميع الاهتمام بها و المشاركة فى الاضافة اليها باذن الله. و قد وجد العديد من الجرويات المهتمة ببعض اجزاءها ، لذا تم اضافة هذه الاقسام املا ان تثري المعرفة فى هذه المجالات باذن الله. و باذن الله سيلي ذلك التطرق الى لغة ال R و يتميز هذا التطبيق بسهولة الاستخدام و وجود امكانيات كبيرة تضم و تتعدي امكانيات الاكسيل و الاكسيس فى التحليل ، و يمكن استخدامه ايضا فى تحليل البيانات الموجودة فى الاكسيل كما سنرى لاحقا باذن الله لا أزعم الخبرة الكبيرة به ، و انا حاليا اتعلمه ، و ساشارككم ما اتعلمه خطوة بخطوة ، و اتوقع باذن الله ان يتحول الكثيرين لاستخدامه تماشيا مع التوجهات الحديثة فى تحليل البيانات ، و لكن كما تحدثنا كثيرا فى هذا المنتدى و نكرر مرة اخرى ان افضل طريفة للتعلم هي الشرح ، فانا ايضا استهدف من هذه السلسلة ليس فقط نشر اللعلم و لكن التعلم ، فباعدادها اكون قد سلكت افضل سبل التعلم . ولتوضيح الامر ، هذا الرسم يوضح انماط التعلم و درجة الاحتفاظ بالمعلومة بها لكل نمط و قد رايته اكثر من مرة و لا اعرف مرجعه العلمي و لكني مقتنع به تماما بالرأي و الواقع و الممارسة خلال السنوات الماضية ، و باستمرار ، حيث كان اخر رد لي فى المنتدى تعلمت مجموعة معلومات اضافية فى موضوع كنت ملما به تماما او بالاصح كنت اعتقد ذلك، الي ان اكتشفت بعض التفاصيل و انا اعد الرد لم اكن ملما بها ، بل و اضاف اعضاء اخرون ردود جديدة اضافت الي معرفتي ، بعد ان ظننت اني ملم به الماما كاملا. و الرسم المرفق من محاضرة لاحد المتحدثين فى منتدى دبي العالمي لادارة المشاريع: باختصرا فان درجة الاحتفاظ بالمعلومة تكون فى ادني مستوياتها بمجرد الاستماع ( 5%) ، ثم ترتفع تدريجيا بالترتيب التالي الاستماع 5% القراءة 10% المشاهدة بالصوت و الصورة 20% البرهنة او مثال عملي 30% الحوار بين مجوعة 50% التجربة بالفعل 75% التدريس للاخرين 90% و هذا يتطابق مع تجربتي فى الحياة و المنتدى و لمستها فى ارتفاع مستوى العديد من الاخوة الفاعلين فى الرد على مواضيع المنتدى حيث تطور مستواهم الفني بدرجة كبيرة جدا حتى اصبحوا خبراء فى مجالاتهم. و سابدأ سلسلة الدروس اعتمادا على الدروس التعليمية المنشورة من قبل فريق البرنامج و هذا رابطها اضغط هنا و باذن الله نتعدي ذلك مستقبلا الدرس الاول طبعا قيل أن نبدأ يلزمك تحميل التطبيق ، و هو تطبيق مجاني مفتوح المصدر و يمكن التحميل من هنا باسم الله نبدأ 1- لنبدأ بفتح التطبيق ، و سنجد الشاشة التالية تظهر لنا و من مجموعة Data على اليسار ، نختار المكون (Widget) المسمي File ثم ننقر على ايقوتة File او نسحبها و سيظهر فى الحالتين فى فى لوحة التصميم Canvas على اليمين ، او كحل ثالث يمكن ان ننقر فى لوحة التصميم بالزر الايمن للماوس و نختار File 2- الخطوة التالية هي تحديد مصدر البيانات الذي سيتم استخدامه ، و هذا بالنقر المزدوج على ايقونه الملف ثم نختار Browse documentation Data Sets من اسفل الشاشة و ستظهر الشاشة التالية مع ملاحظة ان بيانات الملف تظهر بالفعل فى الشاشة السابقة لاني قد سبق لي استخدامه قبل ذلك و بعد ذلك نختار احدي قواعد البيانات الموجودة مع التطبيق و هي IRIS.tab ,و سنري سويا فى دروس قادمة كيف نستبدلها لملف اكسيل او انواع اخرى من البيانات 3- الخطوة التالية تهدف لاظهار البيانات الموجودة فى الملف IRIS للتعرف عليها و لذلك نقوه باختبار المكون (Widget) المسمى Data Table و اضافتها الى لوحة التصميم بنفس الطريقة السابقة لتصبح الشاشة كتالي و يلي ذلك ربط الملف بالبيانات عن طريق سحب القوس الرمادي الخارجي للملف الي ان يتم وصله بالقوس الخارجي الخاص بالداتا و يسمى الشكل السابق الذي يحوي المكونات و قناة الاتصال بينها ب مسار التدفق Workflow و هكذا نكون قد قمنا بعمل اول مسار تدفقي Workflow لنا فى برنامج اورانج و الان نستطيع تصفح البيانات و استعراضها و ذلك بالنقر المزدوج على جدول البيانات Data Table و هذه البيانات تمثل البيانات الخاصة ببعض انواع الزهور من حيث طول الساق و خلافه كما توضح الصورة فإن الsepal هي الأوراق الخضراء الخارجية التي تحيط بالداخلية الملونة و التي تسمي petal أو البتلات ، كما أن iris هي زهرة السوسن و هذا الملف سنسخدمه فى دروس قادمة باذن الله و تمثل الحقول به ما ما يبدو انه مقاسات لطول و عرض اجزاء من الزهور و للتعرف اكثر عليها دعونا نراه بصورة بيانية و كما سنلاحظ الرسوم البيانية هذا غاية فى السهولة من حيث الاعداد و التنسيق و لعمل رسم بياني نختار المكون (Widget) المسمي Scatter Diagram أو مخطط التشتت من مجموعة Visualizaition و الذي يهدف بصفة عامة الي ابراز العلافة بين اي متغيرين ليصبح شكل لوحة التصميم كالتالي: ثم نصل المكون (Widget) الخاص بالملف بمثيله الخاص بمخطط التشتت و بعد ذلك ننقر مرتين على المكون (Widget) الخاص بمخطط التششت ليظهر الرسم البياني التالي و يمكن التعرف على الاوامر الموجودة على يسار الشاشة لتغيير شكل و طريقة الرسم بسهولة و مثلا باختيار Sepal Lengh كنقاط للرسم يظهر الشكل التالي و بذلك ينتهي الدرس الاول ، و أسأل الله التيسير لاستكمال باقي السلسلة و تعلم و نشر ما يفيد الدرس الثاني - اضغط هنا www.officena.net




- 15 replies
-
- 8
-

-
- اورانج
- تحليل البيانات
- (و1 أكثر)
-
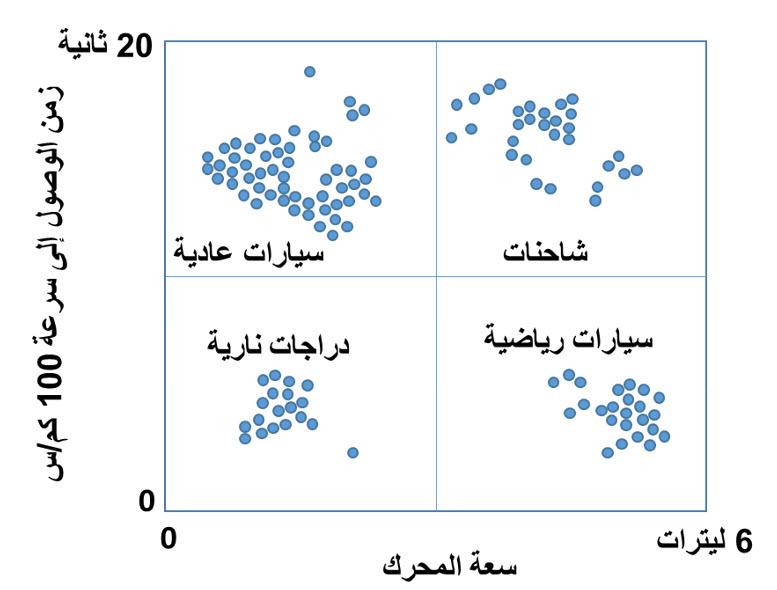
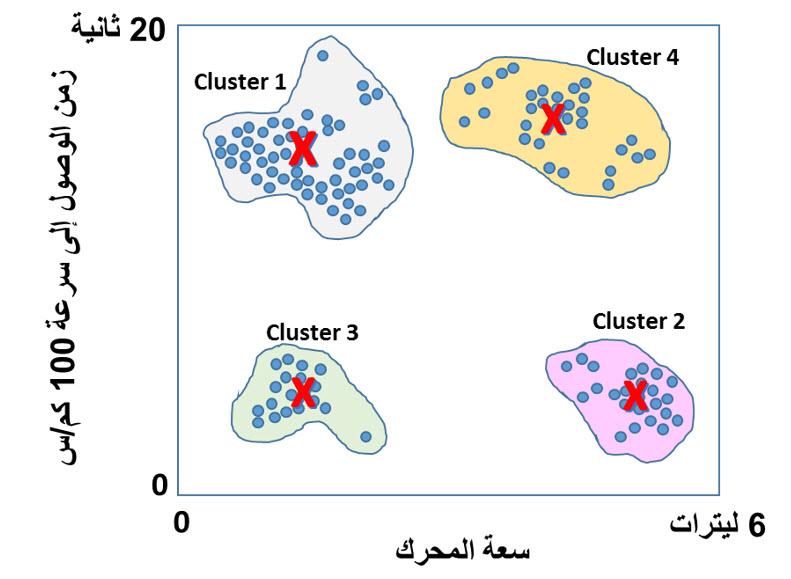
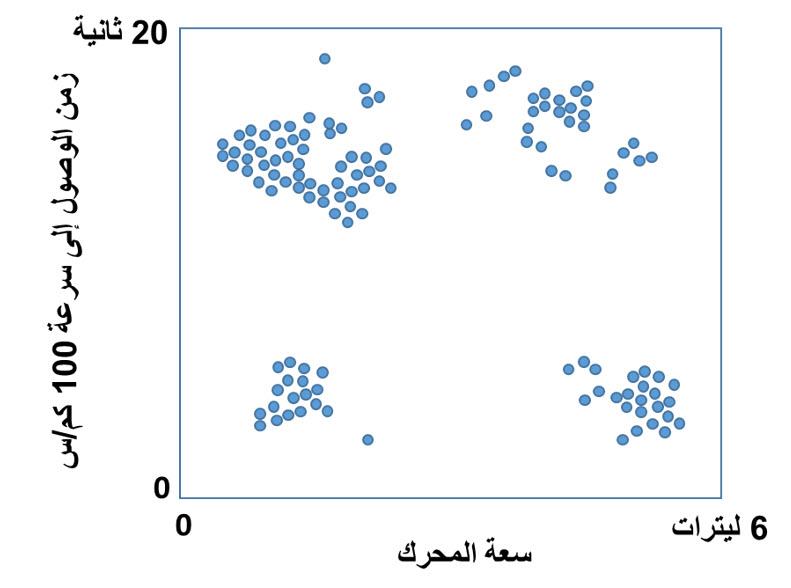
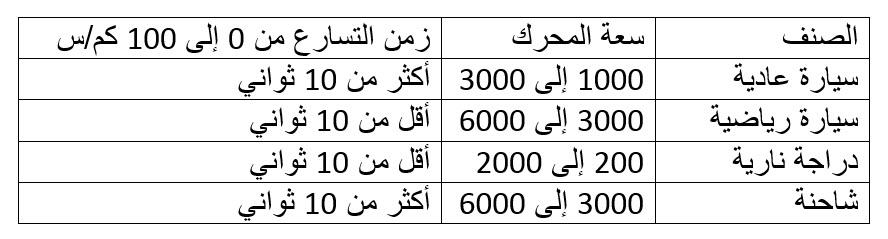
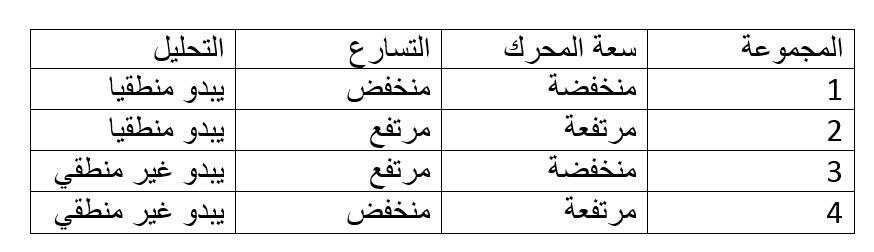
اخترت أسلوبين لتحليل البيانات لشرحهما والمقارنة بنيهما، والأسلوبين هما التجميع Clustering والتصنيف Classification، والسبب لاختياري هذين الأسلوبين أنني كنت محتار تماما في الفرق بينهما، وبالتالي قرأت عنهما الكثير وتوصلت لفهم بسيط لكل منهما والفرق الأساسي بينهما، ولكي أشرحهما سأقوم باستعراض مثال بسيط معكم. تخيل أنك لا تعرف شيء عن المركبات أو السيارات، وتم إعطائك مجموعة كبيرة من البيانات Big Data عن المركبات التي تسير في شوارع مدينتك، وكانت هذه البيانات في صورة جدول يتضمن سعة المحرك باللتر، والزمن الذي تستغرقه المركبة للوصول إلى سرعة 100 كيلومتر/الساعة بالثانية، كما يوضح الرسم البياني أدناه تذكر أنك لا تعرف شيء عن المركبات، ولا تستطيع أن تحدد نوع المركبة، أو حجمها من البيانات المتاحة، ولكن مطلوب منك تحليل البيانات ومحاولة إيجاد علاقات منطقية بينها. هل تستخدم التجميع Clustering أم التصنيف Classification ؟ من المنطقي في هذه الحالة ألا تحاول استخدام التصنيف، فأنت لا تعرف الأصناف الموجودة ومواصفات كل منها، وهذه هي نفس المشكلة التي سيواجهها جهاز الحاسب الآلي الذي يستطيع معالجة البيانات بسرعة ولكن ليس لديه فهم مسبق عن ماهية البيانات. وبالتالي يصبح حتميا استخدام التجميع Clustering، وهو عبارة عن تجميع البيانات القريبة من بعضها البعض في مجموعة واحدة Cluster، وإيجاد المتوسط الحسابي لها بحيث تكون النقاط المشمولة في المجموعة أقرب للمتوسط الحسابي للمجموعة الخاصة بها من المتوسط الحسابي لأي مجموعة أخرى، كما يوضح الشكل أدناه. والسؤال الآن، ما الذي استفدناه من هذا التجميع؟ دعونا أولا نسجل بعض الملاحظات عن المجموعات الأربعة التي ظهرت لدينا: - المجموعة 1 تتضمن أكبر عدد من النقاط وتتميز بانخفاض سعة المحرك وارتفاع زمن الوصول إلى 100 كيلومتر/الساعة (أي انخفاض القدرة على التسارع) - المجموعة 2 تتضمن تقريبا أقل عدد من النقاط وتتميز بارتفاع سعة المحرك وانخفاض زمن الوصول إلى 100 كيلومتر/الساعة (أي ارتفاع القدرة على التسارع) - المجموعة 3 تتضمن عدد قليل من النقاط وتتميز بانخفاض سعة المحرك وانخفاض زمن الوصول إلى 100 كيلومتر/الساعة (أي ارتفاع القدرة على التسارع) - المجموعة 4 تتضمن عدد متوسط من النقاط وتتميز بارتفاع سعة المحرك وارتفاع زمن الوصول إلى 100 كيلومتر/الساعة (أي انخفاض القدرة على التسارع) دعونا نقوم بتحليل هذه النتائج من وجهة النظر المنطقية: نفترض الآن أنك تريد أن تفهم أسباب منطقية وعدم منطقية النتائج، طبعا ستلجأ لصديق يفهم جيدا في أنواع المركبات وأصنافها، وسيكون رده في الغالب كما يلي: · المجموعة 1 ذات سعة المحرك المنخفضة والتسارع المنخفض هي السيارات العادية Passenger Vehicles · المجموعة 2 ذات سعة المحرك المرتفعة والتسارع المرتفع هي السيارات الرياضية Sports Cars · المجموعة 3 ذات سعة المحرك المنخفضة والتسارع المرتفعة هي الدراجات النارية Motor Cycles · المجموعة 4 ذات سعة المحرك المرتفعة والتسارع المنخفض هي الشاحنات Trucks إذن التجميع لا يبدأ بتصنيفات محددة ولكنه يصل إلى الأصناف من خلال التجميع والتحليل، وطبعا في هذا المثال لم نصل إلى أي اكتشافات أو أنماط جديدة لأننا تطرقنا إلى موضوع مفهوم مسبقا وتصنيفاته معروفة، ولكن فائدة التجميع تظهر في تحليل البيانات غير محددة التصنيف. فعلى سبيل المثال لو توفرت لديك معلومات عن أعمار المتسوقين وأنواع المشروبات التي يشترونها، يمكنك تجميعها في مجموعات تحدد من خلالها إذا ما كان العمر يؤثر على اختيار المشروب، ونوعية المشروب المفضل لفئات عمرية محددة، وبالتالي يتم توجيه المواد الإعلانية للأشخاص طبقا لاختياراتهم المسبقة. دعونا الآن نتطرق إلى التصنيف، وسنستخدم نفس مثال المركبات، في هذه الحالة قبل أن تبدأ في تحليل البيانات ستسأل صديقك خبير المركبات عن الأصناف المختلفة للمركبات، وفي الغالب سيعطيك جدول بالأصناف المختلفة كما يلي: وستقوم بناء على هذه الجدول تصنيف المركبات إلى الأصناف الأربعة كما يوضح الرسم التالي: أو بمعني آخر العيب الرئيسي للتصنيف أنه قد يمنعك من اكتشاف علاقات جديدة بين البيانات أرجو أن أكون قد تمكنت من توضيح الفرق بين التجميع والتصنيف، والله ولي التوفيق دائما